Alpha Chen
alpha
Whee, it’s time for Advent of Code again! 37/24 for Day 1. We’ll see how often I’ll be able to leaderboard this year.
 21
21
 0
0
 3
3
Alpha Chen
alphaShow content
# p ARGF.read.split("\n\n").map { _1.each_line.map(&:to_i).sum }.max
p ARGF.read.split("\n\n").map { _1.each_line.map(&:to_i).sum }.sort[-3..-1].sum
I always find the code for my leaderboarding attempts (especially the successful ones) to be an interesting look into both my initial instincts for breaking down a problem, as well as which parts of Ruby I use to solve it.
 0
0
2
0
0
2
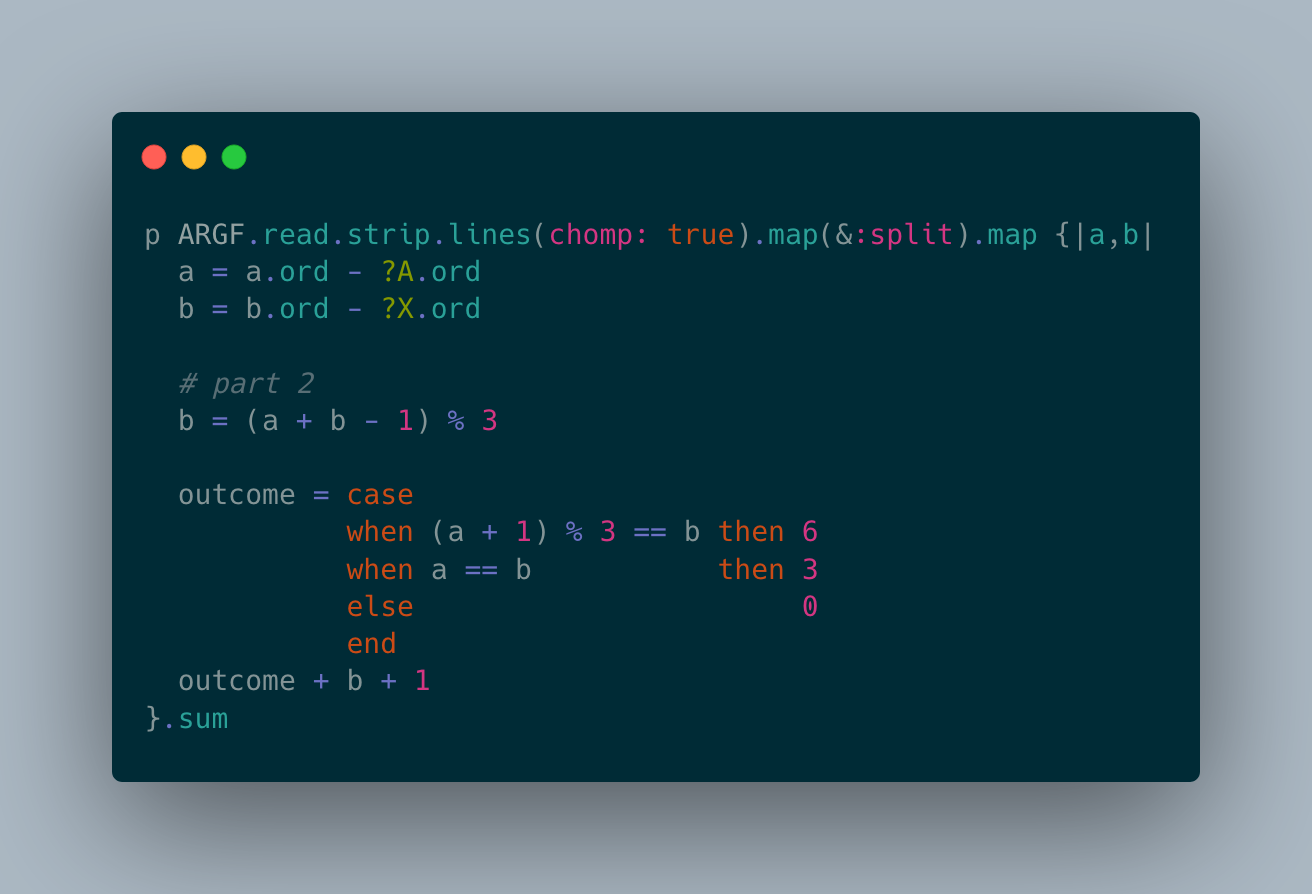
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
3 00:04:06 290 0 00:06:07 158 0
priorities = ((?a..?z).to_a + (?A..?Z).to_a).map.with_index { [_1, _2+1] }.to_h
# part 1
# p ARGF.read.lines(chomp: true).map {|line|
# len = line.length
# a = line[0...len/2]
# b = line[len/2..]
# priorities.fetch((a.chars & b.chars)[0])
# }.sum
p ARGF.read.lines(chomp: true).each_slice(3).map {|chunk|
priorities.fetch(chunk.map(&:chars).inject(&:&)[0])
}.sum
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
4 00:03:18 452 0 00:03:37 147 0
p ARGF.read.lines(chomp: true)
.map { _1.split(?,) }
.map {|x| x.map { _1.split(?-).map(&:to_i) }}
.map {|(a,b),(x,y)| [(a..b), (x..y)] }
# .count {|a,b| (a.cover?(b.begin) && a.cover?(b.end)) || (b.cover?(a.begin) && b.cover?(a.end)) }
.count {|a,b| (a.cover?(b.begin) || a.cover?(b.end)) || (b.cover?(a.begin) || b.cover?(a.end)) }
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
5 00:07:57 216 0 00:09:52 230 0
setup, moves = ARGF.read.split("\n\n")
setup = setup
.lines(chomp: true)
.map(&:chars)
.transpose
.map {|col| col.select { _1 =~ /[A-Z]/ }}
.reject(&:empty?)
moves = moves.scan(/move (\d+) from (\d+) to (\d+)/).map { _1.map(&:to_i) }
moves.each do |n,from,to|
# n.times {
# setup[to-1].unshift(setup[from-1].shift)
# }
setup[to-1].unshift(*setup[from-1].shift(n))
end
p setup.map(&:first).join
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
6 00:04:58 1987 0 00:05:25 1413 0
# p ARGF.read.chars.each_cons(4).with_index.find {|a,i| a.uniq.size == 4 }.last + 4
p ARGF.read.chars.each_cons(14).with_index.find {|a,i| a.uniq.size == 14 }.last + 14
Alpha Chen
alphaHaving fun playing with BQN for Advent of Code this year!
# •Show 4 + ⊐⟜1 ⍷⊸≡¨ <˘ 4↕ •FChars "../day_06.txt"
•Show 14 + ⊐⟜1 ⍷⊸≡¨ <˘ 14↕ •FChars "../day_06.txt"
Alpha Chen
alphaShow content
Oof, that one was rough - my approach for part one was not usable at all for part two.
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
8 00:22:03 3656 0 00:36:40 3129 0
# grid = ARGF.read.lines(chomp: true).map {|row| row.chars.map { [_1.to_i, false] }}
# def mark!(ary)
# max = -1
# ary.each do |tree_counted|
# if tree_counted.first > max
# max = tree_counted.first
# tree_counted[1] = true
# end
# end
# end
# grid.each { mark!(_1) }
# grid.each { mark!(_1.reverse) }
# grid.transpose.each { mark!(_1) }
# grid.transpose.each { mark!(_1.reverse) }
# p grid.sum { _1.count(&:last) }
grid = ARGF.read.lines(chomp: true).map { _1.chars.map(&:to_i) }
def score(grid, y, x)
tree = grid[y][x]
[
(0...y).to_a.reverse.slice_after {|i| grid[i][x] >= tree }.first,
(y+1...grid.size).slice_after {|i| grid[i][x] >= tree }.first,
(0...x).to_a.reverse.slice_after {|i| grid[y][i] >= tree }.first,
(x+1...grid.size).slice_after {|i| grid[y][i] >= tree }.first,
].compact.map(&:size).inject(:*)
end
p grid.flat_map.with_index {|row,y|
row.map.with_index {|tree,x|
score(grid, y, x)
}
}.max
Alpha Chen
alphaShow content
Refactoring so the logic is clearer:
grid = ARGF.read.lines(chomp: true).map { _1.chars.map(&:to_i) }
def each(grid)
return enum_for(__method__, grid) unless block_given?
transposed = grid.transpose
grid.each.with_index do |row, y|
row.each.with_index do |tree, x|
col = transposed[x]
sight_lines = [
(0...x).map { row[_1] }.reverse,
(x+1...row.size).map { row[_1] },
(0...y).map { col[_1] }.reverse,
(y+1...row.size).map { col[_1] },
]
yield tree, sight_lines
end
end
end
p each(grid).count {|tree, sight_lines|
sight_lines.any? { _1.empty? || tree > _1.max }
}
p each(grid).map {|tree, sight_lines|
sight_lines
.map {|sl| sl.slice_after { _1 >= tree }.first }
.compact
.map(&:size)
.inject(:*)
}.max
Brian Ziman
BrianZiman@mastodon.socialShow content
@alpha You are human after all! I think this may be the only one I've ever finished before you!
0
0
1
Alpha Chen
alphaThere’s a lesson here in that the refactored version, which shares logic between the solutions, is barely shorter than the two independent implementations that don’t share any logic at all. The abstraction doesn’t make the code any shorter, but it does unify the approach to solving both parts.
I don’t have a pithy lesson here or anything, but thought it was an interesting parallel to real-world development, which doesn’t often show up in my Advent of Code solutions.
0
0
0
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
9 00:22:45 2529 0 00:26:50 1006 0
require "set"
motions = ARGF.read.scan(/([RLUD])\s+(\d+)/).map { [_1, _2.to_i] }
class Snake
def initialize
@knots = Array.new(10) { [0, 0] }
end
def tail = @knots.last
def move!(dir)
delta = case dir
when ?L then [ 0, -1]
when ?U then [ 1, 0]
when ?R then [ 0, 1]
when ?D then [-1, 0]
else fail dir.inspect
end
@knots[0] = @knots[0].zip(delta).map { _1 + _2 }
@knots = @knots[1..].inject([@knots[0]]) {|knots, tail|
head = knots.last
delta = head.zip(tail).map { _1 - _2 }
knots << if delta.any? { _1.abs > 1 }
tail.zip(delta.map { _1.clamp(-1, 1) }).map { _1 + _2 }
else
tail
end
}
end
end
snake = Snake.new
seen = Set.new
motions.each do |dir, distance|
distance.times do
snake.move!(dir)
seen << snake.tail
end
end
p seen.size
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
10 00:28:35 6047 0 00:36:57 3289 0
Whew, this one took me a while to just grok! Not even going to bother doing any refactoring, ugh.
instructions = ARGF.read.lines(chomp: true)
adds = {}
cycle = 1
instructions.each do |instruction|
cycle += case instruction
when /noop/
1
when /addx (-?\d+)/
adds[cycle+1] = $1.to_i
2
else fail instruction
end
end
xs = (0..adds.keys.max).inject([1]) { _1 << _1.last + adds.fetch(_2, 0) }
p 20.step(by: 40, to: 220).map { [_1, xs[_1]] }.sum { _1 * _2 }
puts 6.times.map {|y|
40.times.map {|x|
cycle = 40*y + x + 1
xx = xs.fetch(cycle, xs.last)
(-1..1).cover?(x - xx) ? ?# : ?.
}.join
}.join("\n")
Alpha Chen
alphaThe most obtuse code I’ve written so far for Advent of Code, for sure. But still shockingly concise. Feel like there must be a better way to get xs, perhaps even combining the two loops, but I don’t think I really have the brains for it right now.
0
0
0
drbrain
drbrain@mastodon.socialShow content
@robdaemon @alpha it’s MatzLisp!
0
0
1
Alpha Chen
alphaShow content
Back to a relatively decent position on the global leaderboard! Only somewhat gross code, mostly in the parsing.
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
11 00:16:07 233 0 00:20:48 167 0
Monkey = Struct.new(:id, :items, :operation, :test, :throw_to)
monkeys = ARGF.read.split("\n\n").map {|raw|
raw = raw.lines(chomp: true)
id = raw.shift.match(/\d+/)[0].to_i
starting_items = raw.shift.match(/: (.+)/)[1].split(", ").map(&:to_i)
operation_ = raw.shift.match(/: new = (.+)/)[1]
operation = ->(old) { eval(operation_) }
test = raw.shift.match(/\d+/)[0].to_i
t = raw.shift.match(/\d+/)[0].to_i
f = raw.shift.match(/\d+/)[0].to_i
throw_to = ->(n) { (n % test).zero? ? t : f }
Monkey.new(id, starting_items, operation, test, throw_to)
}
max_worry = monkeys.map(&:test).inject(:*)
inspections = Hash.new(0)
# 20.times do
10_000.times do
monkeys.each do |monkey|
until monkey.items.empty?
inspections[monkey.id] += 1
item = monkey.items.shift
item = monkey.operation.(item)
# item /= 3
item %= max_worry
to = monkey.throw_to.(item)
monkeys[to].items << item
end
end
end
p inspections.values.max(2).inject(:*)
Alpha Chen
alphaShow content
@robdaemon I think a lot of the Ruby I write tends to be in a relatively functional style. In some ways, starting to learn an array programming language (BQN) is feeling somewhat familiar from how comfortable I am with enumerables/iterators in Ruby/Rust.
0
0
0
Alpha Chen
alphaShow content
This is a little cleaner, but so much more fragile.
monkeys = ARGF.read.scan(/Monkey (\d+):
Starting items: ((?~\n))
Operation: new = ((?~\n))
Test: divisible by (\d+)
If true: throw to monkey (\d+)
If false: throw to monkey (\d+)
/m).map {|id, items, operation, test, t, f|
Monkey.new(
id.to_i,
items.split(", ").map(&:to_i),
operation,
test.to_i,
t.to_i,
f.to_i,
)
}
Brian Ziman
BrianZiman@mastodon.social@alpha That is really cool. I spent 45 minutes writing a parser for this in Java... not a language built for rapid prototyping or text parsing!
0
0
1
Alpha Chen
alphaShow content
Parslet is nice.
class MonkeyParser < Parslet::Parser
rule(:num) { match("[0-9]").repeat.as(:num) }
rule(:space) { match("\\s").repeat }
rule(:newline) { str("\n") }
rule(:monkey) {
space >> str("Monkey ") >> num.as(:id) >> str(":") >>
space >> str("Starting items: ") >> ( num >> ( str(", ") >> num ).repeat ).as(:items) >>
space >> str("Operation: new = ") >> (newline.absent? >> any).repeat.as(:op) >>
space >> str("Test: divisible by ") >> num.as(:test) >>
space >> str("If true: throw to monkey ") >> num.as(:true) >>
space >> str("If false: throw to monkey ") >> num.as(:false) >>
space
}
rule(:monkeys) { monkey.repeat }
root(:monkeys)
end
class MonkeyTransform < Parslet::Transform
rule(num: simple(:x)) { x.to_i }
rule(
id: simple(:id),
items: sequence(:items),
op: simple(:op),
test: simple(:test),
true: simple(:t),
false: simple(:f),
) {
Monkey.new(id, items, op, test, t, f)
}
end
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
12 00:20:13 1031 0 00:28:51 1414 0
Finished with this code here:
height_map = ARGF.read.lines(chomp: true).map(&:chars)
.each.with_index.with_object({}) do |(row,y),map|
row.each.with_index do |height,x|
map[[y,x]] = height
end
end
s, e = height_map.invert.values_at(?S, ?E)
height_map[s] = ?a
height_map[e] = ?z
# part one
# queue = [s]
# visited = { s => 0 }
# until visited.has_key?(e)
# current = queue.shift
# moves = visited.fetch(current)
# neighbors = [
# [-1, 0],
# [ 1, 0],
# [ 0, -1],
# [ 0, 1],
# ].map { current.zip(_1).map {|a,b| a + b } }
# .select { height_map.has_key?(_1) }
# .reject { visited.has_key?(_1) }
# .select { height_map.fetch(_1).ord - 1 <= height_map.fetch(current).ord }
# neighbors.each do |y,x|
# visited[[y,x]] = moves + 1
# queue << [y,x]
# end
# queue.sort_by { visited.fetch(_1) }
# end
# p visited.fetch(e)
# part two
queue = [e]
visited = { e => 0 }
loop do
current = queue.shift
moves = visited.fetch(current)
neighbors = [
[-1, 0],
[ 1, 0],
[ 0, -1],
[ 0, 1],
].map { current.zip(_1).map {|a,b| a + b } }
.select { height_map.has_key?(_1) }
.reject { visited.has_key?(_1) }
.select { height_map.fetch(current).ord <= height_map.fetch(_1).ord + 1 }
if a = neighbors.find { height_map.fetch(_1) == ?a }
p moves + 1
break
end
neighbors.each do |y,x|
visited[[y,x]] = moves + 1
queue << [y,x]
end
queue.sort_by { visited.fetch(_1) }
end
Alpha Chen
alphaShow content
Refactored to be nicer and smarter:
class HeightMap
NEIGHBORS = [[0, -1], [-1, 0], [0, 1], [1, 0]]
def initialize(heights)
@heights = heights
end
def shortest(from:, to:, &cond)
frontier = [from]
visited = { from => 0 }
until frontier.empty? || to.any? { visited.has_key?(_1) }
current = frontier.shift
NEIGHBORS.each do |delta|
candidate = current.zip(delta).map { _1 + _2 }
next if visited.has_key?(candidate)
next unless cand_height = @heights[candidate]
next unless cond.(@heights.fetch(current), cand_height)
visited[candidate] = visited.fetch(current) + 1
frontier << candidate
end
frontier.sort_by { visited.fetch(_1) }
end
visited.find {|k,v| to.include?(k) }.last
end
end
heights = ARGF.read.lines(chomp: true).map(&:chars)
.flat_map.with_index {|row,y|
row.map.with_index {|height,x| [[y, x], height] }
}.to_h
s, e = heights.invert.values_at(?S, ?E)
heights[s] = ?a
heights[e] = ?z
hm = HeightMap.new(heights)
# part one
p hm.shortest(from: s, to: [e]) { _1.ord + 1 >= _2.ord }
# part two
as = heights.select { _2 == ?a }.map(&:first)
p hm.shortest(from: e, to: as) { _1.ord - 1 <= _2.ord }
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
13 00:21:02 1075 0 00:23:47 706 0
This one was an exercise in reading comprehension, oof.
def compare(left, right)
case [left, right]
in [left, nil]
1
in [Integer, Integer]
left <=> right
in [Array, Array]
left.zip(right).each do |left, right|
case compare(left, right)
when -1 then return -1
when 0 # no-op
when 1 then return 1
end
end
(left.size == right.size) ? 0 : -1
else
compare(Array(left), Array(right))
end
end
# part one
# pairs = ARGF.read.split("\n\n")
# pairs = pairs.map {|pair| pair.lines(chomp: true).map { eval(_1) }}
# p pairs.map.with_index {|(left,right),i|
# [compare(left, right), i+1]
# }.select {|cmp,_| cmp == -1 }.sum(&:last)
# part two
pairs = ARGF.read.lines(chomp: true).reject(&:empty?).map { eval(_1) }
pairs << [[2]] << [[6]]
pairs = pairs.sort { compare(_1, _2) }
a = pairs.index([[2]])
b = pairs.index([[6]])
p (a+1)*(b+1)
Alpha Chen
alphaShow content
Refactored:
def compare(left, right)
case [left, right]
in [left, nil]
1
in [Integer, Integer]
left <=> right
in [Array, Array]
left.zip(right).each do |left, right|
case compare(left, right)
when -1 then return -1
when 0 # no-op
when 1 then return 1
end
end
(left.size == right.size) ? 0 : -1
else
compare(Array(left), Array(right))
end
end
# part one
pairs = ARGF.read.split("\n\n")
pairs = pairs.map {|pair| pair.lines(chomp: true).map { eval(_1) }}
p pairs.map.with_index.select {|(l,r),_| compare(l, r) == -1 }.map { _1.last + 1 }.sum
# part two
pairs = pairs.flatten(1)
dividers = [[[2]], [[6]]]
pairs.concat(dividers)
pairs = pairs.sort { compare(_1, _2) }
p pairs.map.with_index.to_h.values_at(*dividers).map { _1 + 1 }.inject(:*)
Alpha Chen
alphaShow content
-------Part 1-------- -------Part 2--------
Day Time Rank Score Time Rank Score
14 00:19:03 560 0 00:23:07 534 0
Brute force.
scan = ARGF.read.lines(chomp: true)
cave = scan.each.with_object({}) {|line, cave|
line.split(" -> ")
.map { _1.split(?,).map(&:to_i) }
.each_cons(2) {|(ax,ay),(bx,by)|
Range.new(*[ax, bx].sort).each do |x|
Range.new(*[ay, by].sort).each do |y|
cave[[x, y]] = ?#
end
end
}
}
x_min, x_max = cave.keys.map(&:first).minmax
y_min, y_max = cave.keys.map(&:last).minmax
inspect_cave = -> {
puts (0..y_max+1).map {|y|
(x_min-1..x_max+1).map {|x|
cave[[x, y]] || ?.
}.join
}.join("\n")
}
# part one
# sands = 0
# loop do
# inspect_cave.()
# sands += 1
# pos = [500, 0]
# while next_pos = [0, -1, 1].map {|dx| pos.zip([dx, 1]).map { _1 + _2 }}.find { cave[_1].nil? }
# pos = next_pos
# break if pos[1] >= y_max
# end
# break if pos[1] >= y_max
# cave[pos] = ?o
# end
# inspect_cave.()
# p sands-1
# part two
cave.default_proc = ->(h,(x,y)) { h[[x, y]] = y == y_max + 2 ? ?# : nil }
sands = 0
loop do
# inspect_cave.()
sands += 1
pos = [500, 0]
while next_pos = [0, -1, 1].map {|dx| pos.zip([dx, 1]).map { _1 + _2 }}.find { cave[_1].nil? }
pos = next_pos
end
break if pos == [500, 0]
cave[pos] = ?o
end
# inspect_cave.()
p sands
Alpha Chen
alphaShow content
I think this must be the least nice code I’ve written so far for Advent of Code.
2
0
1
Brian Ziman
BrianZiman@mastodon.socialShow content
@alpha It's not so bad - it looks pretty similar to my solution.
0
0
1
Alpha Chen
alphaShow content
Couldn’t help myself and refactored it a bit:
scan = ARGF.read.lines(chomp: true)
cave = scan.each.with_object({}) {|line, cave|
line.split(" -> ")
.map { _1.split(?,).map(&:to_i) }
.each_cons(2) {|(ax,ay),(bx,by)|
Range.new(*[ax, bx].sort).each do |x|
Range.new(*[ay, by].sort).each do |y|
cave[[x, y]] = ?#
end
end
}
}
def cave.to_s
x_min, x_max = keys.map(&:first).minmax
y_min, y_max = keys.map(&:last).minmax
(0..y_max+1).map {|y|
(x_min-1..x_max+1).map {|x|
self.fetch([x, y], ?.)
}.join
}.join("\n")
end
def pour_sand(cave, stop:)
return enum_for(__method__, cave, stop:) unless block_given?
loop do
# puts cave
pos = [500, 0]
while next_pos = [0, -1, 1].map {|dx| pos.zip([dx, 1]).map { _1 + _2 }}.find { cave[_1].nil? }
pos = next_pos
break if stop.(*pos)
end
break if stop.(*pos)
cave[pos] = ?o
yield pos
end
end
y_max = cave.keys.map(&:last).max
# part one
p pour_sand(cave, stop: ->(_, y) { y >= y_max }).count
# part two
cave.delete_if { _2 == ?o } # reset cave
cave.default_proc = ->(_,(_,y)) { y == y_max + 2 ? ?# : nil }
p pour_sand(cave, stop: ->(x, y) { [x, y] == [500, 0] }).count + 1
Alpha Chen
alphaShow content
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
15 00:42:00 2529 0 10:12:53 12339 0
A tough part two - called time on it last night and left an inefficient algorithm run overnight. Came back in the morning and it was only 25% of the way through, but thought of another optimization tweak (jumping to the end of a no-beacon range when the cursor’s x position is farther than the sensor’s x position) that allowed it to finish in just a few minutes.
require "set"
sensors_and_beacons = ARGF.read
.scan(/Sensor at x=(-?\d+), y=(-?\d+): closest beacon is at x=(-?\d+), y=(-?\d+)/)
.map { _1.map(&:to_i) }
.flatten
.each_slice(2)
# part one
row = 2_000_000
# row = 10
no_beacons = []
sensors_and_beacons.each_slice(2) do |sensor, beacon|
dist = sensor.zip(beacon).sum { (_1 - _2).abs }
dy = (row - sensor[1]).abs
next if dy > dist
dx = dist - dy
x_min, x_max = [sensor[0]-dx, sensor[0]+dx].sort
no_beacons << (x_min..x_max)
end
# remove covered ranges
no_beacons = no_beacons.reject {|x| (no_beacons - [x]).any? { _1.cover?(x) }}
# merge ranges
no_beacons = no_beacons.inject([no_beacons.shift]) {|no_beacons, range|
next no_beacons if no_beacons.any? { _1.cover?(range) }
if overlap = no_beacons.find { _1.cover?(range.begin) }
range = (overlap.end + 1..range.end)
end
if overlap = no_beacons.find { _1.cover?(range.end) }
range = (range.begin..overlap.begin-1)
end
no_beacons << range
}
p no_beacons.sum(&:size) - sensors_and_beacons.to_a.select { _2 == row }.uniq.size
# part two
find_sab = ->(x, y) {
sensors_and_beacons.each_slice(2).find {|sensor, beacon|
dist = sensor.zip(beacon).sum { (_1 - _2).abs }
dist >= sensor.zip([x, y]).sum { (_1 - _2).abs }
}
}
max = 4_000_000
# max = 20
x = 0
y = 0
loop do
p y if (y % 10_000).zero?
sensor, _ = find_sab.(x, y)
dx = sensor[0] - x
if dx >= max / 2
dy = sensor[1] - y
y += dy.positive? ? 2 * dy + 1 : 1
end
loop do
sensor, beacon = find_sab.(x, y)
if sensor.nil?
p 4_000_000 * x + y
exit
end
dist = sensor.zip(beacon).sum { (_1 - _2).abs }
dy = (sensor[1] - y).abs
dx = (dist - dy).abs
x = sensor[0] + dx + 1
if x > max
x = 0
break
end
end
y += 1
break if y > max
end
Alpha Chen
alphaShow content
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
18 00:02:28 46 55 01:00:30 2053 0
What a wild swing between part one and part two. I thought my initial approach was inherently wrong on part two, and worked on a few other ideas for a long time before realizing I just needed a .uniq to make it performant.
cubes = ARGF.read.lines(chomp: true).map { _1.split(?,).map(&:to_i) }
# part one
# p cubes.sum {|cube|
# 6 - cubes.count {|other|
# cube.zip(other).map { _1 - _2 }.map(&:abs).sum == 1
# }
# }
deltas = [
[-1, 0, 0],
[ 1, 0, 0],
[ 0, -1, 0],
[ 0, 1, 0],
[ 0, 0, -1],
[ 0, 0, 1],
]
bounds = cubes.transpose.map(&:minmax).map {|(min, max)| (min-1..max+1) }
cubes = cubes.to_h { [_1, true] }
corners = [
[bounds[0].begin, bounds[1].begin, bounds[2].begin],
[bounds[0].begin, bounds[1].begin, bounds[2].end],
[bounds[0].begin, bounds[1].end, bounds[2].begin],
[bounds[0].begin, bounds[1].end, bounds[2].end],
[bounds[0].end, bounds[1].begin, bounds[2].begin],
[bounds[0].end, bounds[1].begin, bounds[2].end],
[bounds[0].end, bounds[1].end, bounds[2].begin],
[bounds[0].end, bounds[1].end, bounds[2].end],
]
frontier = [corners[0]]
seen = Hash.new
until frontier.empty?
current = frontier.shift
neighbors = deltas.map {|delta| current.zip(delta).map { _1 + _2 }}
.select {|neighbor| bounds.zip(neighbor).all? {|(bound, i)| bound.cover?(i) }}
seen[current] = neighbors.any? { cubes.has_key?(_1) }
frontier.concat(neighbors.reject {|neighbor| seen.has_key?(neighbor) || cubes.has_key?(neighbor) })
frontier.uniq!
end
p cubes.keys.sum {|cube|
neighbors = deltas.map {|delta| cube.zip(delta).map { _1 + _2 }}
neighbors.count { seen.has_key?(_1) }
}
Brian Ziman
BrianZiman@mastodon.socialShow content
@alpha Wow you crushed me on part 1, but I guess I beat you on part 2... I really enjoy seeing your solutions!
1
0
1
Alpha Chen
alphaShow content
@BrianZiman Thanks! That’s what I’m hoping when I post them, but I don’t know how many people actually read them!
1
0
0
Alpha Chen
alphaShow content
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
20 00:37:21 845 0 00:38:37 557 0
This one was kind of annoying. Easy algorithm, took almost half an hour to realize that the real data had duplicates numbers in it, when the sample data did not. Ugh.
list = ARGF.read.lines(chomp: true).map(&:to_i)
list = list.map { _1 * 811589153 }
list = list.map.with_index { [_2, _1] }
10.times do
(0...list.size).each do |i|
j = list.index {|ii,_| ii == i }
_, n = list.delete_at(j)
j += n
j %= list.size
list.insert(j, [i, n])
end
end
list = list.map(&:last)
i = list.index(0)
p [1000, 2000, 3000].sum { list.fetch((i + _1) % list.size) }
Brian Ziman
BrianZiman@mastodon.socialShow content
@alpha At least one!
0
0
1
Alpha Chen
alphaShow content
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
21 00:01:55 7 94 00:39:34 989 0
Hilarious leaderboard rank for part one due to metaprogramming shenanigans. :3
Kind of gross implementation for part two though, I think.
monkeys = ARGF.read.lines(chomp: true).to_h {|line| line.split(": ") }
# part one
# monkeys.each do |name, body|
# define_method(name) do
# eval(body)
# end
# end
# p root
# part two
sub_monkeys = monkeys.delete("root").split(" + ")
monkeys.delete("humn")
monkeys.each do |name, body|
define_method(name) do
eval(body)
end
end
target, unknown = sub_monkeys.partition { eval(_1) rescue nil}.map(&:first)
target = eval(target)
monkeys = monkeys.to_h {|monkey, job|
a, op, b = job.split(" ")
[monkey, { op:, a:, b: }]
}
monkeys["humn"] = { op: :humn }
def apply(monkeys, monkey)
job = monkeys.fetch(monkey)
case op = job.fetch(:op)
when nil
job.fetch(:a).to_i
when :humn
:humn
else
a = apply(monkeys, job.fetch(:a))
b = apply(monkeys, job.fetch(:b))
if a.is_a?(Integer) && b.is_a?(Integer)
eval([a, op, b].join(" "))
else
[job.fetch(:op), a, b]
end
end
end
tree = apply(monkeys, unknown)
def reverse(target, tree)
loop do
case tree
in :humn
return target
in [op, Integer, b]
a = tree.fetch(1)
case op
when ?* then target /= a
when ?+ then target -= a
when ?- then target = a - target
else fail tree.inspect
end
tree = b
in [op, a, Integer]
b = tree.fetch(2)
case op
when ?- then target += b
when ?/ then target *= b
when ?* then target /= b
when ?+ then target -= b
else fail tree.inspect
end
tree = a
else
fail tree.inspect
end
end
end
p reverse(target, tree)
Brian Ziman
BrianZiman@mastodon.socialShow content
@alpha I had a really elegant solution for part 2, with a typo in it, so when it didn't work, I assumed my approach was wrong, and simply evaluated the tree by hand with a calculator. Then I went back and fixed my typo. 🤦♂️
0
0
1
Alpha Chen
alphaShow content
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
23 00:36:25 623 0 00:38:28 525 0
grove = {}
ARGF.read.lines(chomp: true).each.with_index do |row, y|
row.chars.each.with_index do |c, x|
grove[[y,x]] = c == ?#
end
end
dirs = [
[[-1, -1], [-1, 0], [-1, 1]],
[[ 1, -1], [ 1, 0], [ 1, 1]],
[[-1, -1], [ 0, -1], [ 1, -1]],
[[-1, 1], [ 0, 1], [ 1, 1]],
]
(1..).each do |i|
proposals = grove.select { _2 }
.to_h {|(y,x),_|
to = if dirs.flatten(1).none? {|dy,dx| grove[[y+dy, x+dx]] }
[y, x]
elsif dir = dirs.find {|adj| adj.none? {|dy,dx| grove[[y+dy, x+dx]] }}
dy, dx = dir[1]
[y+dy, x+dx]
else
[y, x]
end
[[y,x], to]
}
proposals.each.with_object(Hash.new {|h,k| h[k] = []}) {|(from, to), conflicts|
conflicts[to] << from
}.select { _2.size > 1 }.values.flatten(1).each do |elf|
proposals[elf] = elf
end
if proposals.all? { _1 == _2 }
puts i
exit
end
proposals.each do |from, to|
grove[from] = false
grove[to] = true
end
dirs.push(dirs.shift)
end
# y = grove.select { _2 }.keys.map(&:first).minmax
# x = grove.select { _2 }.keys.map(&:last).minmax
# p Range.new(*y).sum {|y| Range.new(*x).count {|x| !grove[[y,x]] }}
Alpha Chen
alphaShow content
Probably should’ve just turned to Z3 immediately for part two. This only took 5-10 minutes just now, so likely would’ve cut my time in half, at least.
require "z3"
monkeys = ARGF.read.lines(chomp: true).to_h {|line| line.split(": ") }
sub_monkeys = monkeys.delete("root").split(" + ")
monkeys.delete("humn")
solver = Z3::Solver.new
solver.assert Z3.Int(sub_monkeys[0]) == Z3.Int(sub_monkeys[1])
monkeys.each do |name, job|
a, op, b = job.split(" ")
if op.nil?
solver.assert Z3.Int(name) == a.to_i
else
a = a =~ /^\d+$/ ? a.to_i : Z3.Int(a)
b = b =~ /^\d+$/ ? b.to_i : Z3.Int(b)
solver.assert Z3.Int(name) == a.send(op, b)
end
end
fail unless solver.satisfiable?
p solver.model[Z3.Int("humn")]
Alpha Chen
alphaShow content
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
25 00:28:10 1214 0 - - -
This is my “fuck it, use a solver” technique because I didn’t want to think hard and logically figure out the algorithm.
places = (0..).lazy.map { 5 ** _1 }
digits = { ?- => -1, ?= => -2 }
sum = ARGF.read.lines(chomp: true)
.map {|snafu|
snafu.reverse.chars
.map { digits.fetch(_1, _1.to_i) }
.zip(places)
.map { _1 * _2 }
.sum
}.sum
n_places = places.slice_after { 2*_1 >= sum }.take(1).to_a.flatten.reverse
require "z3"
solver = Z3::Solver.new
n_places.each do |place|
solver.assert Z3.Int(place.to_s) <= 2
solver.assert Z3.Int(place.to_s) >= -2
end
solver.assert n_places.map { _1 * Z3.Int(_1.to_s) }.sum == sum
fail unless solver.satisfiable?
p n_places
.map { solver.model[Z3.Int(_1.to_s)].to_i }
.map { digits.invert.fetch(_1, _1) }
.join
Alpha Chen
alphaProbably my worst Advent of Code showing so far, but mostly since I was time-boxing my attempts. Looking at the stats, I spent roughly 30 minutes on average, so that’s not too much time invested. Seems unlikely that I’ll come back and noodle on the ones I gave up on, but who knows.
As usual, written in pretty terse Ruby (unintentionally, no solutions over 100 lines of code), and I mostly avoided doing a ton of refactoring except for some of the earlier days when I wound up with extra time. (Regardless, all original solutions are in git history.)
https://git.kejadlen.dev/alpha/advent-of-code/src/branch/main/2022/ruby
-------Part 1-------- --------Part 2--------
Day Time Rank Score Time Rank Score
25 00:28:10 1214 0 - - -
23 00:36:25 623 0 00:38:28 525 0
21 00:01:55 7 94 00:39:34 989 0
20 00:37:21 845 0 00:38:37 557 0
18 00:02:28 46 55 01:00:30 2053 0
17 00:42:46 636 0 - - -
15 00:42:00 2529 0 10:12:53 12339 0
14 00:19:03 560 0 00:23:07 534 0
13 00:21:02 1075 0 00:23:47 706 0
12 00:20:13 1031 0 00:28:51 1414 0
11 00:16:07 233 0 00:20:48 167 0
10 00:28:35 6047 0 00:36:57 3289 0
9 00:22:45 2529 0 00:26:50 1006 0
8 00:22:03 3656 0 00:36:40 3129 0
7 00:21:41 959 0 00:27:39 984 0
6 00:04:58 1987 0 00:05:25 1413 0
5 00:07:57 216 0 00:09:52 230 0
4 00:03:18 452 0 00:03:37 147 0
3 00:04:06 290 0 00:06:07 158 0
2 00:11:40 3887 0 00:14:04 2142 0
1 00:00:57 37 64 00:01:29 24 77
Alpha Chen
alpha@BrianZiman Didn’t feel like thinking about how to do the 2nd part efficiently!
0
0
1